魔兽世界关于圣骑士第五层天赋下圣洁怒火与神圣意志的取舍
2013-10-20 23:58:26 作者:hyz_h 来源: 浏览次数:0
摘要:第五层天赋下圣洁怒火与神圣意志的取舍 ——以某种装备下血精灵圣骑士为模型的数学实验
摘要:根据现在主流观点,惩戒骑第五层天赋在面对单体boss时,选择圣洁怒火天赋,受益为本层三个天赋中收益最高,然而,我们通过对以某种装备标准模型下的惩戒骑进行模拟,最终发现实际上圣洁怒火收益最高这种说法并非通用,而应该根据装备情况,对第五层天赋进行选择。

关键词:数学模拟,惩戒骑,神圣意志,圣洁怒火
在《魔兽世界》这款游戏中,圣骑士这个职业对单体木桩输出数据仅受第五层天赋影响,第六层天赋在单体boss战中,最大化伤害的选择毫无疑问应该是处决审判,而第五层天赋的不同,则从根本上影响了惩戒骑的输出模式和输出节奏,在广泛的观点中,一般认为第五层天赋选择圣洁怒火,即延长复仇之怒(使圣骑士伤害和治疗效果提高20%)持续时间延长50%(10)秒,并且在复仇之怒持续期间内,愤怒之锤的冷却时间缩短50%,能获得最大收益,但是本实验利用SimulationCraft对版本号为5.4.0 (17345)版本下惩戒骑的伤害模拟,获得了与普遍观念不同的结果。
实验前提:
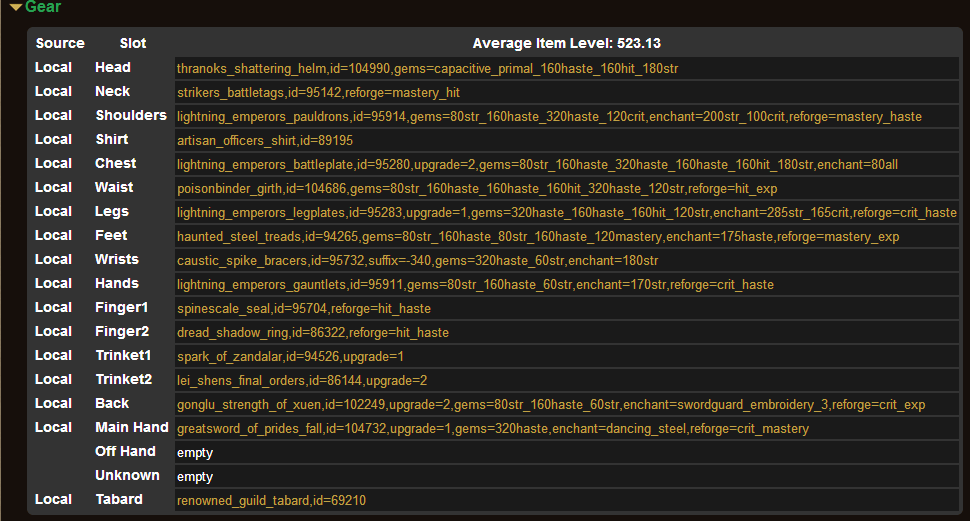
该惩戒骑装备为:
从上图,我们可以看见,该模型武器装等为540+4,身上平均装等为523.12,没有T16套装,而拥有4T15套装
属性统计为:
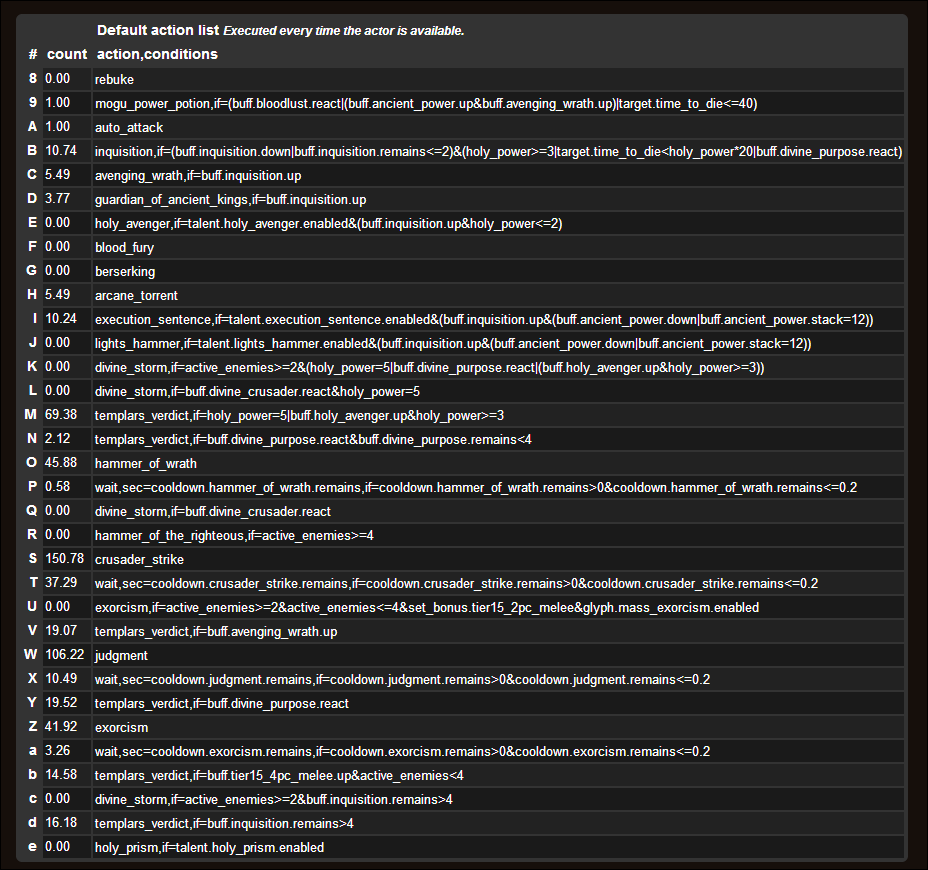
技能循环为SimulationCraft默认惩戒骑技能循环:
上述为实验用的惩戒骑的数据,变量为第五层天赋选择圣洁怒火或神圣意志,为了保证尽可能降低随机误差,我们将实验重复次数设定为SimulationCraft单次模拟的最高上限50000次,并建立在不同延迟状态下(Low为100毫秒;Medium为300毫秒;High为500毫秒,所有有CD的技能,其CD都会按照世界延迟的设置进行随机延长。随机延长的分布采用正态分布,标准差为10%,期望为世界延迟的值。)
和满团队BUFF与单精通BUFF下不同的输出数据模拟的数学模型。
实验结果:
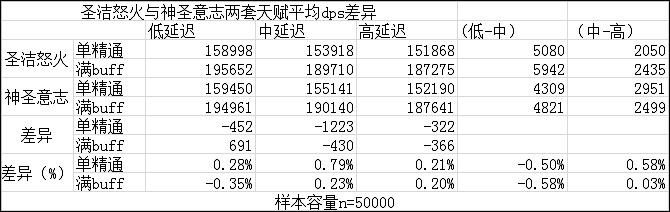
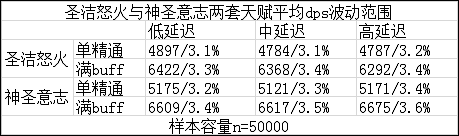
实验模拟DPS结果如下表:
数据分析:
通过SimulationCraft中的统计工具,可知:
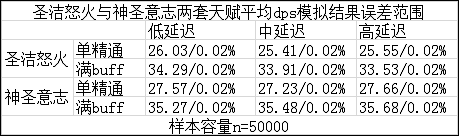
1.模拟中95%置信度内数据可视为小于随机误差,各次DPS模拟结果误差范围如下表:
2.DPS波动范围=(95%置信度-5%置信度)/2,各次DPS模拟的波动范围如下表:
结论:
通过对数据的分析,我们可知:
在该模型下,选用神圣意志天赋的DPS略高于圣洁怒火,这种差异并非来自统计误差(P<0.05),但是二者的DPS并无显著的统计差异(P>0.05),同时,神圣意志天赋下的DPS上下波动大于圣洁怒火,但是这种波动性同样没有显著差异(P>0.05)
造成该结果的原因可能是因为该模型的装备(平均装等523.12)与武器装等差异较大(540弹性武器,一次升级)。
该模型下,神圣意志的期望DPS在大多数情况下略高于圣洁怒火,同时受到BUFF和网络状态的影响,在全BUFF低延迟下,圣洁怒火的期望DPS稍高于神圣意志,但是随着延迟的升高,神圣意志的DPS逐渐上升,网络状态在中延迟到高延迟下,对神圣意志和圣洁怒火两个天赋的DPS差异影响较小,然而在从低延迟到中延迟的过程中,圣洁怒火将会损失更多的DPS,而网络状况对神圣意志天赋所提供的DPS的影响一直小于圣洁怒火。而团队BUFF和网络状况的优化可以使圣洁怒火所能提供的DPS大大提升。
附:
首先,我们在讨论一个天赋的伤害高低的情况时,一般都是默认采用蒙特卡洛法
那么蒙特卡洛法的一个典型状况就是——
手动几十张打木桩图的话统计误差一般都大于0.05,所以没法拿来做数据分析
即使是同一个玩家在同一个场景下产生的样本,都很难具有连续稳定的结果。这是由于大多数职业的输出都比较复杂,玩家不可能长时间稳定地保持注意力;数据收集的误差受玩家技巧影响,不同的玩家玩同一个角色可能会有不同的反应时间,长时间保持输出会导致疲劳犯错等因素所导致。
要达到可供分析的数据精度,所需的数据量太大。例如,一场典型的团队首领战斗,作战时间通常在400-500秒左右。要获得有建模研究价值的数据,误差至少要在1%以内,这就需要约50份战斗数据样本。而随着精确度要求的提高,所需的样本数量将呈指数增长,这样的增长在一份样本耗时400-500秒的情况下,是无法做到的。更何况通常的建模,需要不止一个角色的数据,此时样本数需求又将成倍增长。
而神圣意志和圣洁怒火,在这个测试结果下,神圣意志和圣洁怒火的统计结果依旧可以看出神圣意志带来的dps高于圣洁怒火,不是误差带来的,但是这个差异小于圣洁怒火天赋本身造成的dps波动 ,因此从统计学上,不能认为神圣意志和圣洁怒火两套天赋存在显著性差异
相关报道:
- 熊猫人武学探秘之金钟罩
- 25H雷电王座隐藏首领莱登战术讲解
- 魔兽30分钟200次级好运符:5.3周常库卡隆物资收集...
- 5.3萨尔回归,攻占剃刀岭:暗矛起义前瞻部落篇...
- 挺进奥格瑞玛,玩家自制魔兽5.3精彩预告片!...
- 参与炉石传说测试有机会获得魔兽世界飞马坐骑...
- 魔兽世界5.2PVP武器附魔“辉煌暴君”展示...
- 种田小巨集